Search the Blog
Categories
- Books & Reading
- Broadband Buzz
- Census
- Education & Training
- General
- Grants
- Information Resources
- Library Management
- Nebraska Center for the Book
- Nebraska Memories
- Now hiring @ your library
- Preservation
- Pretty Sweet Tech
- Programming
- Public Library Boards of Trustees
- Public Relations
- Talking Book & Braille Service (TBBS)
- Technology
- Uncategorized
- What's Up Doc / Govdocs
- Youth Services
Archives
Subscribe
Category Archives: Preservation
Throwback Thursday: Mill and Electric Light Plant, Cedar Rapids, Nebraska
Nebraska Memories is here with another #ThrowbackThursday!

This postcard has a colorized photograph from 1907-1917 that shows the mill and electric light power plant in Cedar Rapids, Nebraska, along with its surrounding landscape.
This image is owned and published by History Nebraska. They digitized content from the John Nelson and the J. A. Anderson collection. John Nelson came to Nebraska with his parents at the age of seventeen from Sweden. His photographs tell the story of small town life in Nebraska during the first decades of the twentieth century.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Posted in General, Nebraska Memories, Preservation
Tagged Cedar Rapids, History Nebraska, Postcard, Throwback Thursday
Leave a comment
Throwback Thursday: Dog Walking on Tight Rope
Gather ‘round for this #ThrowbackThursday!

This black and white photograph postcard is from around 1907-1917. It shows a crowd of people standing around a stage, watching a dog walking across a tightrope suspended from a frame and placed over a stage set up on a city street. A man on the stage stands below the dog, looking up as it crosses.
This image is owned and published by History Nebraska. They digitized content from the John Nelson and the J. A. Anderson collection. John Nelson came to Nebraska with his parents at the age of seventeen from Sweden. His photographs tell the story of small town life in Nebraska during the first decades of the twentieth century.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Hodgman Ambulance
We’re back with another #ThrowbackThursday!

This 8” x 10” glass plate negative shows a Hodgman ambulance from the year 1922. The ambulance is white with black trim, white wheel tires, and curtains in the back. A plaque just under the window of the front passenger door reads “Hodgman” and another plaque over the windshield reads “Ambulance.”
This image is published and owned by Townsend Studio, which has been in continuous operation since its foundation in 1888 in Lincoln, Nebraska. The studio holds a collection of glass plate and acetate negatives of early Lincoln and its residents.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Posted in General, Nebraska Memories, Preservation
Tagged glass plate negative, Hodgman, Throwback Thursday, Townsend Studio
Leave a comment
Throwback Thursday: Flag Print Clothing
Happy fourth of July #ThrowbackThursday!

This black and white photograph on a postcard shows man and a woman walking together. The woman is wearing an American flag printed skirt and hat and the man has an American flag print hat. Perhaps they are celebrating the 4th of July!
This image is owned and published by History Nebraska. They digitized content from the John Nelson and the J. A. Anderson collection. John Nelson came to Nebraska with his parents at the age of seventeen from Sweden. His photographs tell the story of small town life in Nebraska during the first decades of the twentieth century.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Seeking Nebraska Yearbooks!

Do you know of or have access to free digital collections of Nebraska yearbooks? We would love to link them in our collection! We’re looking for both High School and College yearbooks!
Comment below or email us if you have a free digital collection of Nebraska yearbooks you’d like to share with us!
You can see the current collection at https://nebraskaccess.nebraska.gov/websites/Yearbooks.asp
Throwback Thursday: Epworth Lake Park
Hope you’re keeping cool this #ThrowbackThursday!

This 14 x 9 cm color postcard shows a view of Epworth Lake Park in Lincoln, Nebraska from around 1901-1907. In the lake are people in a row boat near a dock and wooden house to the right. The lake is surrounded by trees and other buildings are seen beyond the trees. The name Epworth is misspelled on the card as “Epsworth Lake Park, Lincoln, Nebr.”
The Epworth Association was formed in 1897 with ties to the Methodist Church and patterned after the program and meeting grounds at Lake Chautauqua, New York. A large area southwest of Lincoln, Nebraska, along Salt Creek was purchased and Epworth Lake was dredged near its center and filled by the creek. Buildings erected included a dormitory, hotel, four restaurants, post office, an amphitheater seating 500, and a huge, roofed, open-sided amphitheater which seated between 2,500 and 3,000 people. Many small cabins and 857 wooden, raised tent bases were also built to accommodate vacationing families. The park could provide accommodations for 2,500 and by 1910-11 it was in full swing. The Burlington Railroad built a spur line from Lincoln to the park offering summer specials. Because evening programs and Chautauqua were popular, it was common for 25 railroad cars to wait outside the gates to return attendees to Lincoln after the shows. Daily admission was 25 cents or an 8-day pass for $1. Speakers included Booker T. Washington, Enrico Caruso, Theodore Roosevelt, William Jennings Bryan, and Howard Taft. During the summer daily attendance ran from 2,000 – 2,500. With the advent of the automobile and the ability of city dwellers to go anywhere, in 1930, only 13,682 admissions were recorded for the entire year. In 1935 torrential rains nearly destroyed the camp grounds and in 1940 the Epworth League moved its programs to Bethany Park. In about 1966 the land was willed to the City of Lincoln and became Wilderness Park.
— McKee, James L. “Remember When: Memories of Lincoln”. Lincoln: J & L Lee Co., 1998, p. 17.
This image is published and owned by the Omaha Public Library. They have a large collection of 1,100+ postcards and photographs of the Omaha area.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Posted in General, Nebraska Memories, Preservation
Tagged Epworth Lake, Epworth Park, Lincoln Nebraska, Postcard, Throwback Thursday
Leave a comment
Throwback Thursday: Welcome Sign, Crawford NE
Take some time to enjoy the great outdoors this #ThrowbackThursday!

This 4″ x 6″ black and white postcard shows the now-famous sign that was erected at the entry of Pinney Ranch along White River in Dawes County. It reads, “Notice: Hunt and Fish all you Damn please! When the bell rings come to dinner. B.G. Pinney, First Erected in 1887.” Just below the sign the postcard reads “Greetings from Crawford, Nebr.” The ranch was owned by Bailey G. (“BG”) Pinney from 1864-1938.
This image is published by the Crawford Public Library, and owned by the Crawford Historical Society and Museum. They partnered together to digitize a number of images of the Crawford area in the late 1800s and early 1900s.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Linotype NPG
We’re back with another #ThrowbackThursday!

This 8” x 10” glass plate negative was taken in June of 1915, as shown by the calendar in the back of the room advertising the Nebraska State Fair in Lincoln. The negative shows off a wooden room with two linotype machines, one currently in use.
This image is published and owned by Townsend Studio, which has been in continuous operation since its foundation in 1888 in Lincoln, Nebraska. The studio holds a collection of glass plate and acetate negatives of early Lincoln and its residents.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: New Moon
Happy #ThrowbackThursday, did you know there’s a new moon tonight?

This black and white photograph on a postcard shows a photo of the night sky, taken by John Nelson, focusing on the new moon with stars through the treetops. The photographer’s initials appear in the lower right corner, with the J imposed on the N, and the title “The New Moon” is written in the lower left hand corner.
This image is owned and published by History Nebraska. They digitized content from the John Nelson and the J. A. Anderson collection. John Nelson came to Nebraska with his parents at the age of seventeen from Sweden. His photographs tell the story of small town life in Nebraska during the first decades of the twentieth century.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Bookmobile at Nehawka Public Library
Let’s take a drive down memory lane this #ThrowbackThursday!

This 4-1/8″ x 2-1/2″ black and white photograph dated 11/09/1937 shows several woman standing beside a bookmobile parked on Maple Street outside of the log cabin building of Nehawka Public Library, which continues to serve as a library to this day. The panel doors on the truck are open, showing books on shelves inside, and several of the woman are either reading or posing with a book. Among the woman are Isadore Sheldon Tucker on the far left and Evelyn Wolph on the far right. Isadore Sheldon Tucker’s father built Sheldon General Store in 1888 and Miss Wolph was a long time 4-H leader in Cass County.
This image is published by the Nebraska Library Commission. The collections include material on the history of libraries in the state of Nebraska, items from the 1930s related to the Nebraska Public Library Commission bookmobile, as well as items showcasing the history of Nebraska’s state institutions.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Edwin Lyndon May Jr. and Dog
This #ThrowbackThursday is extra adorable!

This 4″x6″ glass plate negative is a portrait photograph of Edwin Lyndon “Ned” May Jr. and a small dog. Edwin was born in Nebraska, December 15, 1904, and the photograph is dated October 16, 1906 making him just under two years old in the portrait. He was the son of Edwin and Jennette May, and according to the 1920 census, the family was living in Beatrice, Nebraska, where his parents ran a hotel. Later in life Edwin married Evelyn Johnson on October 8, 1942, in Jackson County, Missouri. He died at the age of 89 on May 9, 1994, in Pierce, Nebraska.
This image is published as part of the Boston Studio Project collection, and is owned by both them and the Thorpe Opera House Foundation. The Boston Studio Collection consists of over 68,000 negatives that record life in and around David City, Nebraska from 1893 to 1979.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: The Rose Bower at Hanscom Park
Remember to stop and smell the roses on this #ThrowbackThursday!

This 13.5 x 8.5 cm color postcard shows a lovely view of a rose bower at Hanscom Park, one of Omaha’s oldest parks. The 50-acre tract was donated to the city in 1872 by Andrew J. Hanscom and James Megeath. There is a long bower covered in pink roses with a woman standing to the right in an off-white skirt, jacket and hat. The reverse is postmarked 1912 over a one cent stamp featuring Benjamin Franklin in profile (attached upside down) along with a handwritten message:
Postmark 1912
Miss Veda Wenstrand
Essex
Iowa
Rt #3
Hello how you was I am fine and dandy what are you doing now days I am working hard all the time are you coming down this way sun will are you game [unreadable due to fading writing] I am game all the time [unreadable]

This image is published and owned by the Omaha Public Library. They have a large collection of 1,100+ postcards and photographs of the Omaha area.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Posted in General, Nebraska Memories, Preservation
Tagged Color postcards, Hanscom Park, Omaha, Omaha Public Library, Throwback Thursday
Leave a comment
Throwback Thursday: Edward Blewett Residence
We’re back with another #ThrowbackThursday!

This is a 14” x 10.5” photograph of the home of Edward and Carrie Blewett, dated around 1900 – 1903. Located at 1217 Nye Ave. in Fremont, Nebraska; the home was built in 1884 and seems to suggest an eclectic style Victorian home with some loosely based Chateauesque influences. Some of the Chateauesque details include: very tall and ornate chimneys, the iron cresting and finials on the roof, the pyramid shaped hipped roof on the tower, the double belt courses which band the home, and the canopied entrance door. This home was purchased in 1903 by Frank Fowler and was heavily remodeled to create his Neoclassical style Westfield Acres.
This image is owned by the Dodge County Historical Society, and published by Keene Memorial Library. Both are located in Fremont, Nebraska, and they worked as partners to digitize and describe content owned by the historical society. The collection of photographs documents life in Fremont in the late 1800s and early 1900s.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Girl Standing In Tree
Happy May #ThrowbackThursday!

This black and white photograph postcard is of a young girl in a light colored dress and tights. She’s posed up in the branches of a tree. The girl remains unidentified but appears to be one of the nieces of the photographer, John Nelson, who came to Nebraska with his parents at the age of seventeen from Sweden. His photographs tell the story of small town life in Nebraska during the first decades of the twentieth century. This postcard is from around 1907-1917.
This image is owned and published by History Nebraska. They digitized content from the John Nelson and the J. A. Anderson collection.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Two Oaks
It’s the #ThrowbackThursday before Arbor Day!

This sepia-toned 5-3/8” x 3-3/8” postcard is dated October 26, 1911; but the photograph of the two tall oak trees framing the view was likely from several years earlier. It appears to be taken from Mount Vernon Cemetery on Cemetery Hill to the east of Peru, Nebraska. You can see Mount Vernon Hall on the State Normal School campus in the distance. There is a one-cent Benjamin Franklin profile postage stamp on the back, along with this letter:
Peru Nebr.
R. E. Bailey
Oct 26 1911
7 AM
Miss Edna Livingston
Elgin
Nebr.
Hello! Am still in this vale of times[?] and sorrow. How is everything at Elgin? I am working hard this year, at present am carrying twenty four hours. Am teaching Phys Geo. in the ninth grade. Also getting some drill in making plans. I suppose the C.C. is still in Antelope Co? Have you played beast, bird or fish lately?

These images are published by the Nebraska Library Commission. Their collections include material on the history of libraries in the state of Nebraska, items from the 1930s related to the Nebraska Public Library Commission bookmobile, as well as items showcasing the history of Nebraska’s state institutions.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Harriet Fonda and Gordon Reefe in “The Romantic Age” 1927
Its another #ThrowbackThursday from Nebraska Memories!

This 8.5″ x 11″ black and white photograph of a 19 year old Harriet Fonda and Gordon Reefe seated together in costume for “The Romantic Age” production has the caption “Harriett Fonda and Gordon Reefe in ‘The Romantic Age’ 1927″ overlaid. Harriet is spelled incorrectly (Harriett) in the caption. This is believed to be a copy of a photograph that was recreated at an unknown time with added artwork and captioning for use in an Omaha Community Playhouse celebration or display. “The Romantic Age” was written by A. A. Milne.
This image is published by the Omaha Community Playhouse. Their collection includes digitized images of the Playhouse and some of its performances.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: “Cornhusker Rose: Waltz Ballad”
It’s a musical #ThrowbackThursday!

Dated 1922, “Cornhusker Rose” is a love song written by Howard Adamson, a long-time resident of Lincoln, Nebraska. He dedicated it to his sweetheart Miss Vivian Hanson, whose picture is on the cover of the sheet music. Below is a transcript of the lyrics; you can also listen to a performance of the ballad on the Nebraska Memories archive, performed by Carolyn Dow, mezzo-soprano, and Linda Marsh Helfman, piano.
Verse 1:
I found a rose, sweet in repose,
Blooming in love’s garden fair.
Beauty so rare, none can compare,
Fairest of all anywhere.
And even though we’re apart dear,
Still you are near to my heart.
Cornhusker rose of Nebraska,
Prettiest flow’r that I know.
Cornhusker rose of Nebraksa,
The sweetest rose that grows.
Those golden hours together,
Hours that I spent dear with you.
For there in love’s bower is blooming one flow’r.
‘Tis the cornhusker rose of my heart.
Verse 2:
Cornhusker girl, my heart’s a whirl,
I’m thinking only of you.
Cornhusker girl, Oh! What a pearl,
Promise you will be true.
For’neath the blue skies above dear,
You taught the meaning of love.
Cornhusker rose of Nebraska,
Prettiest flow’r that I know.
Cornhusker rose of Nebraksa,
The sweetest rose that grows.
Those golden hours together,
Hours that I spent dear with you.
For there in love’s bower is blooming one flow’r.
‘Tis the cornhusker rose of my heart.
This image and musical performance is published and owned by the Polley Music Library (Lincoln City Libraries, Lincoln, Nebraska), which contains just over two hundred fifty pieces of Nebraska sheet music, as well as concert programs, manuscripts, theatre programs, photographs, and other Nebraska memorabilia which features an element of music. You can also listen to a dozen performances of selections from this music collection performed by local musicians.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Water Supply Map of Omaha, Nebraska
Nebraska Memories is here with another #ThrowbackThursday!
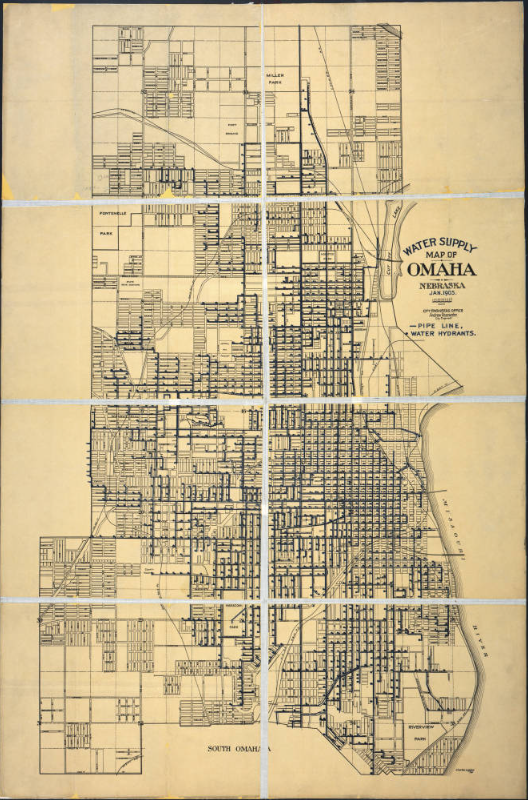
This map from January 1905 shows the water supply system of Omaha, Nebraska. A legend shows that the dark blue lines on the map represent the city’s pipelines, and the dark blue dots represent water hydrants. There is also a scale for size. Printed between the scale and the legend it says “City Engineers Office, Andrew Rosewater, City Engineer.”
This image is published and owned by the Omaha Public Library, and is specifically part of their collection of Omaha-related maps dating from 1825 to 1922. They also have a large collection of 1,100+ postcards and photographs of the Omaha area.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories
/participation.aspx for more information.
Posted in General, Nebraska Memories, Preservation
Tagged City Engineer, Map, Omaha, Omaha Nebraska, Omaha Public Library, Throwback Thursday, Water Supply Map
Leave a comment
Throwback Thursday: Dorothy Rich
It’s time for another #ThrowbackThursday from Nebraska Memories!

This 4 x 6 glass plate negative is a full-figure portrait photograph of Dorothy Rich, seated at a small wooden table and serving tea to her doll and her stuffed bunny. Dorothy was born May 3rd, 1903 in Nebraska to Riley G. and Georgie A. Rich. Her father worked as a physician in David City, Nebraska.
This image is published as part of the Boston Studio Project collection, and is owned by them and the Thorpe Opera House Foundation. The Boston Studio Collection consists of over 68,000 negatives that record life in and around David City, Nebraska from 1893 to 1979.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.
Throwback Thursday: Col. Prebble and Army Staff
Happy #ThrowbackThursday from Nebraska Memories!

This 7” x 5” black and white formal photograph was taken in 1944. It shows the first commanding officer of the Sioux Army Depot, Colonel Prebble, along with his staff, which includes two women in uniform sitting in the front row. The Sioux Army Depot was established March 23, 1942 about seven miles west of Sidney, Nebraska. The depot was responsible for warehousing and distributing ammunition and general supplies. It was eventually deactivated on June 30, 1967.
This image is published and owned by the Cheyenne County Historical Society and Museum, located in Sidney, Nebraska. Their collection holds many historical photographs of people and places in Sidney, Fort Sidney, Potter, Dalton, and other communities and sites in the county.
See this collection and many more on the Nebraska Memories archive!
The Nebraska Memories archive is brought to you by the Nebraska Library Commission. If your institution is interested in participating in Nebraska Memories, see http://nlc.nebraska.gov/nebraskamemories/participation.aspx for more information.

